Introduction
Accessing the Open Data Hub
This is the website of the Open Data Hub documentation, a collection of technical resources about the Open Data Hub project. The website serves as the main resource portal for everyone interested in accessing the data or deploying apps based on datasets <Dataset> & APIs provided by the Open Data Hub team.
The technical stuff is composed of:
Catalogue of available datasets.
How-tos, FAQs, and various tips and tricks for users.
Links to the full API documentation.
Resources for developers.
For non-technical information about the Open Data Hub project, please point your browser to https://opendatahub.com/.
Project Overview
The Open Data Hub project envisions the development and set up of a portal whose primary purpose is to offer a single access point to European (Open) Data.
The availability of Open Data from a single source will allow everybody to utilise the Data in several ways:
Digital communication channels. Data are retrieved from the Open Data Hub and used to provide informative services, like newsletters containing weather forecasting, or used in hotels to promote events taking place in the surroundings, along with additional information like seat availability, description, how to access each event, and so on and so forth.
Applications for any devices, built on top of the data, that can be either a PoC to explore new means or new fields in which to use Open Data Hub data, or novel and innovative services or software products built on top of the data.
Internet portals and websites. Data are retrieved from the Open Data Hub and visualised within graphical charts, graphs, or maps.
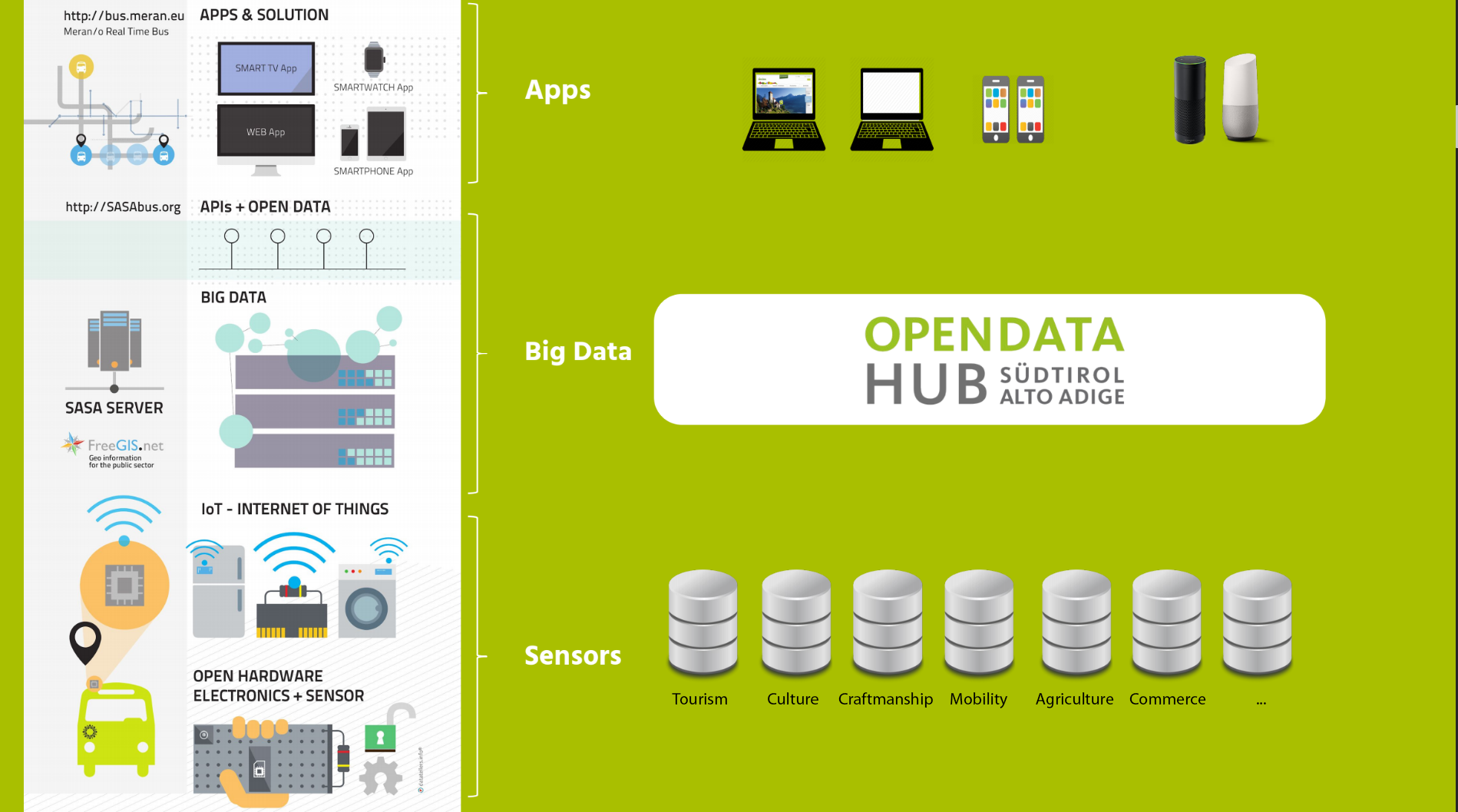
Figure 1 An overview of the Open Data Hub Project.
Figure 1 gives a high level overview of the flow of data within the Open Data Hub: at the bottom, sensors gather data from various domains, which are fed to the Open Data Hub Big Data infrastructure and made available through endpoints to (third-party) applications, web sites, and vocal assistants. A more technical and in-depth overview can be found in Section Open Data Hub Architecture.
All the data within the Open Data Hub will be easily accessible, preferring open interfaces and APIs which are built on existing standards like The Open Travel Alliance (OTA), The General Transit Feed Specification (GTFS), Alpinebits.
The Open Data Hub team also strives to keep all data regularly updated, and use standard exchange formats to facilitate their spreading and use. Depending on the development of the project and the interest of users, more standards and data formats might be supported in the future.
Getting Involved
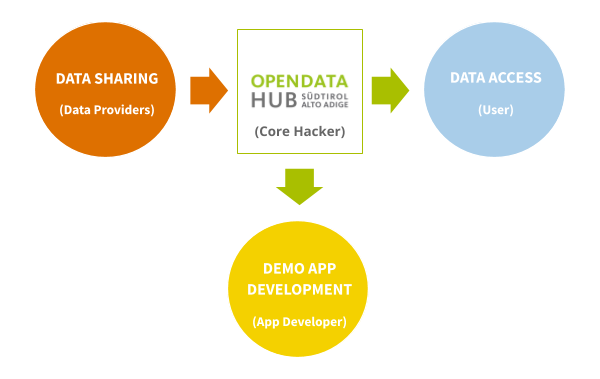
Figure 2 Relations between the actors involved in the Open Data Hub.
The Open Data Hub team welcomes new partners and user to join the project. For this reason, a number of services are offered to help you getting in touch with the project and support you in case you want to either collaborate with the project or simply use the data made available.
The Open Data Hub team envisioned different possibilities to join the project, that are detailed in the remainder of this section, including–but not limited to–reporting bugs in the API or errors in the API output, making feature requests or suggestions for improvement, and even to participate in the development or supply new data to be shared through the Open Data Hub.
Figure 2 shows at a glance the services offered by the Open Data Hub together with the various roles that potential users can play within the Open Data Hub, according to their interest, expertise, skills, and knowledge.
Data Sharing
The Open Data Hub team helps you in various activities: give visibility to your data, identify both suitable, common formats, processing algorithms and licenses to share your data, and to use popular technologies known by application developers.
Data Access
The Open Data Hub team supports software development companies to access to real-time data, by making available to everyone a stable communication channel which uses a machine-readable protocol and an Open Data license, to ensure everybody can easily find all the available data.
Demo App Development
The Open Data Hub team collaborates with companies to design and develop Proof of Concepts and demo software, released under an Open Source License that use data offered by the Open Data Hub. All the software can then either be used as-is–to show and test its potentials, or as a guideline and inspiration to develop new digital products.
Besides the tasks that you find below, you can also help the Open Data Hub project grow and improve by reporting bugs or asking for new features, by following the directions presented in the dedicated section below.
How to Collaborate
This section gives an overview of which tasks you can play when collaborating with the Open Data Hub project.
Depending on your interest on the Open Data Hub Project, we welcome your participation to the project in one of the roles that we have envisioned: User (Data Consumer), App developer, Core Hacker, and Data Provider. Below you can find out a list of tasks that belong to each of these roles; we believe that this list can help you understand which type of contribution you can give to the Open Data Hub project!
As a User I can…
- …explore the data in the datasets.
Choose a dataset from the list of Domains and Datasets and start gathering data from it, by using the documentation provided in this site. You can then provide any kind of feedback on the dataset: reports about any malfunctions, suggestions for improvements or new features, and so on.
Moreover, if you are interested in datasets that are not yet in our collection, get in touch with the Open Data Hub team to discuss your request.
As a Data Provider I can….
- …provide Open Data to the Open Data Hub project.
Share with an Open Data Licence (like e.g.,
 or
or  ) the
data you own, that can prove interesting for the Open Data Hub, for
example because they complement existing data in the Open Data Hub or they
pertain to an area which is not yet covered. Let your Open Data be
freely used by App Developers in their applications.
) the
data you own, that can prove interesting for the Open Data Hub, for
example because they complement existing data in the Open Data Hub or they
pertain to an area which is not yet covered. Let your Open Data be
freely used by App Developers in their applications.
Note
A Data Provider is an entity (be it a private company, a public institution, or a citizen) that gathers data on a regular basis from various sensors or devices and stores them in some kind of machine-readable format.
As an App Developer I can…
- …harvest data exposed by the dataset.
Browse the list of Domains and Datasets to see what types of data are contained in the datasets, and think how they can be used.
For this purpose, we maintain an updated list of the available datasets with links to the API to access them.
- …build an application with the data.
Write code for an app that combines the data you can harvest from the available datasets in various, novel way.
To reach this goal, you need to access the APIs, their documentation, and the datasets. It is then your task to discover how you can reuse the data in your code.
- …integrate Open Data Hub data using Web Components.
The Open Data Hub team and their partner have developed a small library of Web Components that can be integrated in existing web sites or used as guidance to develop new Web Components.
As a Open Data Hub Core Hacker I can…
- …help shape the future of Open Data Hub.
Participate in the development of Open Data Hub: Build new data collectors, extend the functionality of the broker, integrate new datasets on the existing infrastructure, develop new API versions.
Bug Reporting and Feature Requests
This section explains what to do in case you:
have found an error or a bug in the APIs;
like to suggest or require some enhancement for the APIs;
have some requests about the datasets
find typos or any error in this documentation repository;
have an idea for some specific tutorial.
If your feedback is related to the Open Data Hub Core, please create an issue on the relevant github repository of our organization: https://github.com/noi-techpark
If your feedback is related to the Open Data Hub Documentation, please send an email to : our Customer Service will take charge of it.
We keep track of your reports in our bug trackers, where you can also follow progress and comments of the Open Data Hub team members.
Accessing the Open Data Hub
There are lots of alternatives to access the Open Data Hub and its data: interactive and non-interactive, using a browser or the command line.
Various dedicated tutorials are available in the List of HOWTOs section to help you getting started, while in section Getting Involved you can find additional ways to collaborate with the Open Data Hub Team and use the data.
Browser access
Accessing data in the Open Data Hub by using a browser is useful on different levels: for the casual user, who can have a look at the type and quality of data provided; for a developer, that can use the REST API implemented by the Open Data Hub or even check if the results of his app are coherent with those retrieved with the API; for everyone in order to get acquainted with the various methods to retrieve data.
Besides the online tools developed by the Open Data Hub and described in section Quickstart, these other resources can be access using a browser.
Programmatic access
Programmatic and non-interactive access to the Open Data Hub’s dataset is possible using any of the following methods made available by the Open Data Hub team.
AlpineBits client
The AlpineBits Alliance strives to develop and to spread a standard format to exchange tourism data. Open Data Hub allows access to all data produced by AlpineBits using dedicated endpoints:
The AlpineBits HotelData dataset can be access from https://alpinebits.opendatahub.com/AlpineBits/.
See also
The dedicated howto How to access Open Data Hub AlpineBits Server as a client
The AlpineBits DestinationData endpoint is available at https://destinationdata.alpinebits.opendatahub.com/.
Statistical Access with R
R is a free software for statistical analysis that creates also graphics from the gathered data.
The Open Data Hub Team has developed and made available bzar, an R package that can be used to access BZ Analytics data and process them using all the R capabilities. Download and installation instructions, along with example usage can be found on the bzar repository.
API
The APIs are composed of a few generic methods, that can be combined with many parameters to retrieve only the relevant data and then post-processed in the preferred way.
Your best opportunity to learn about the correct syntax and parameters to use is to go to the swagger interface of the tourism or mobility domains and execute a query.
CLI access
Unlike browser access, that provides an interactive access to data, with the option to incrementally refine a query, command line access proves useful for non-interactive, one-directional, and quick data retrieval in a number of scenarios, including:
Scripting, data manipulation and interpolation, to be used in statistical analysis.
Applications that gather data and present them to the end users.
Automatic updates to third-parties websites or kiosk-systems like e.g., in the hall of hotels.
Command line access to the data is usually carried out with the curl Linux utility, which is used to retrieve information in a non-interactive way from a remote site and can be used with a variety of options and can save the contents it downloads, which can them be send to other applications and manipulated.
Your best opportunity to learn about the correct syntax and parameters to use is to go to the swagger interface of the tourism or mobility domains and execute a query: with the output, also the corresponding curl command used to retrieve the data will be shown.
The AlpineBits Client
The AlpineBits Alliance strives to develop and to spread a standard format to exchange tourism data. There are two datasets they developed and keep up to date, that are of particular interest for Open Data Hub users: HotelData and DestinationData.
DestinationData
The AlpineBits DestinationData is a standardisation effort to allow the exchange of information related to mountains, events, tourism. Developed by the AlpineBits Alliance, Destination Data relies on a number of standards (Including json, REST API, Schema.org, OntoUML) to build the AlpineBits DestinationData Ontology, the core result of the effort. The goal of DestinationData it to provide a means to describe events, their location, and additional information on them. For this purpose, the DestinationData Ontology specifies a number of Named Entities used to describe Events and Event Series, Mountain Areas, Places, Trails, Agents, and so on.
The full specification of the ontology, including architecture of the API and description of the datatypes defines can be found in the official Destination Data specs (pdf ).
The reference implementation of AlpineBits DestinationData is provided by Open Data Hub and publicly available at the dedicated endpoint at https://destinationdata.alpinebits.opendatahub.com/.
See also
More information and resources about AlpineBits DestinationData can be found on the official page.
HotelData
The AlpineBits HotelData is meant for data strictly related to hotels and booking, like Inventory Basic, Inventory HotelInfo, and FreeRooms. This dataset can be access from the dedicated endpoint at https://alpinebits.opendatahub.com/AlpineBits/
See also
The dedicated howto How to access Open Data Hub AlpineBits Server as a client.
The official page of AlpineBits HotelData.