How to Access Mobility Data With API v2
The new API v2 (see the description) for the Mobility domain has simplified the access to data; among its features, we recall that there is now one single endpoint from which to retrieve data from all datasets.
The starting point for all actions to be carried out on the datasets made available by the Open Data Hub team is the swagger mobility API home page:
https://swagger.opendatahub.com/?url=https://mobility.api.opendatahub.com/v2/apispec
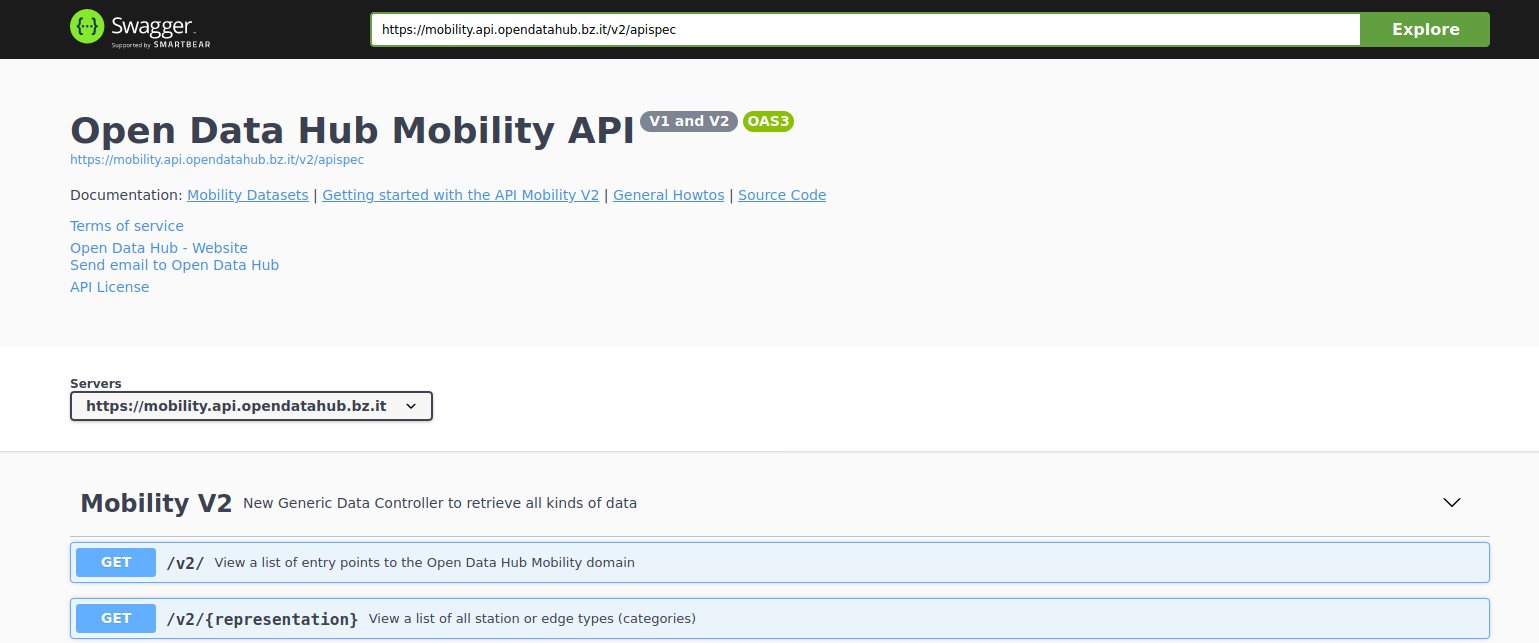
Figure 5 The swagger interface of the Mobility API v2.
From this site, links provide access to documentation about data licencing and use of the API; it is also possible to contact the Open Data Hub team by sending an email to the issue tracker, to ask questions, provide feedback, or to report issues.
When executing queries against the datasets, besides the output data, you will always receive the curl command and the corresponding direct URL, to be used for examples, in scripts. See Example Queries
Getting Started
In the API v2, the central concept is Station: all data come
from a given StationType, whose complete list can be
retrieved by simply opening the second method of the Mobility
V2 controller, /v2/{representation}, then click on
and then on Execute.
Station types in the resulting list can be used in the other methods to retrieve additional data about each of them. To check which station belongs to which datasets, you can check the list of mobility-datasets.
Example Queries
We use some of the techniques presented in section Advanced Data Processing and the Parking dataset to show a few simple queries and see the output they provide.
We recall that the two StationTypes of that datasets are
ParkingStation and ParkingSensor; we start by retrieving all
ParkingStations, leaving all other options to their default values,
and then building two more refined queries, one using the select
clause and one using the where clause:
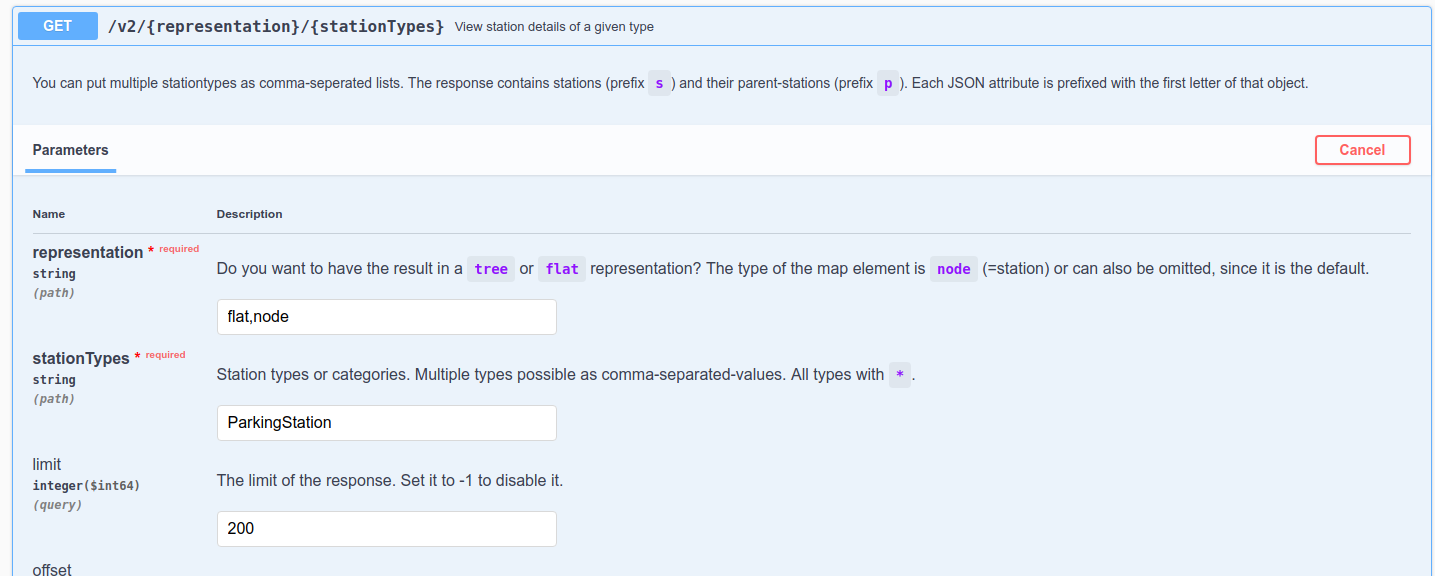
Figure 6 Querying all ParkingStations. |
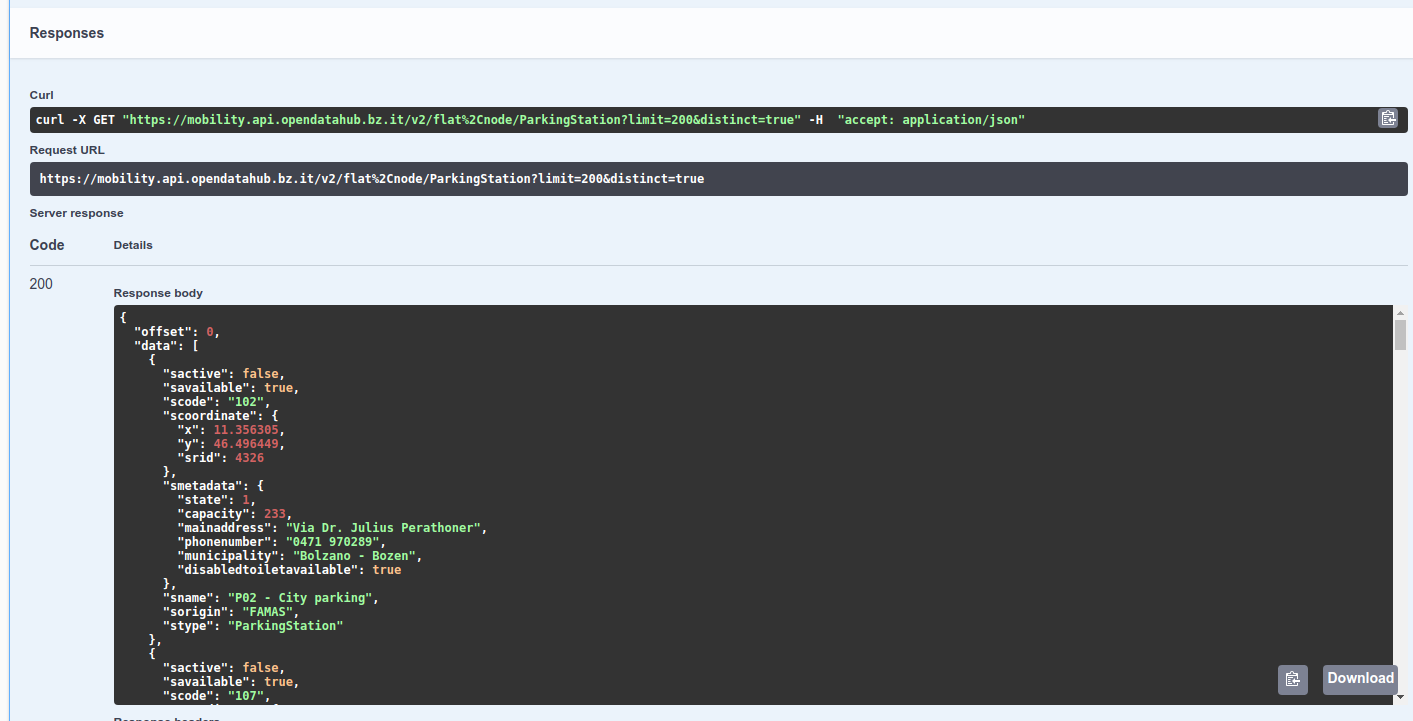
Figure 7 The Output of query. |
Hint
You can copy to the clipboard or download the result of the query by clicking on the bottom-right corner icons.
If we would like to know the capacity of each of the parking lots, we add smetadata.municipality, smetadata.mainaddress, smetadata.capacity to the select clause:

Figure 8 Querying the capacity of parkings. |
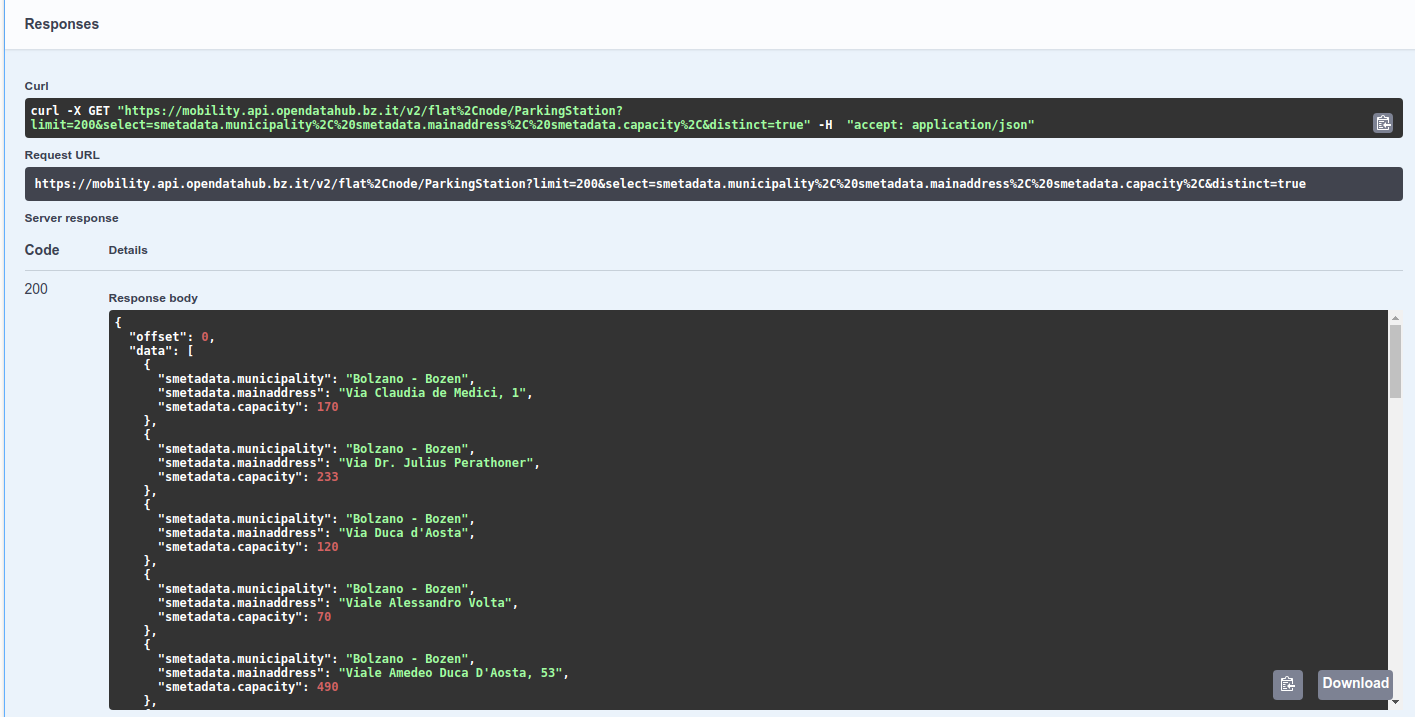
Figure 9 The Output of query. |
Finally, we are interested only in the ParkingStations whose origin is not FAMAS. We need therefore to add the following to the where clause (we also remove the entry added for the previous query in the select clause):
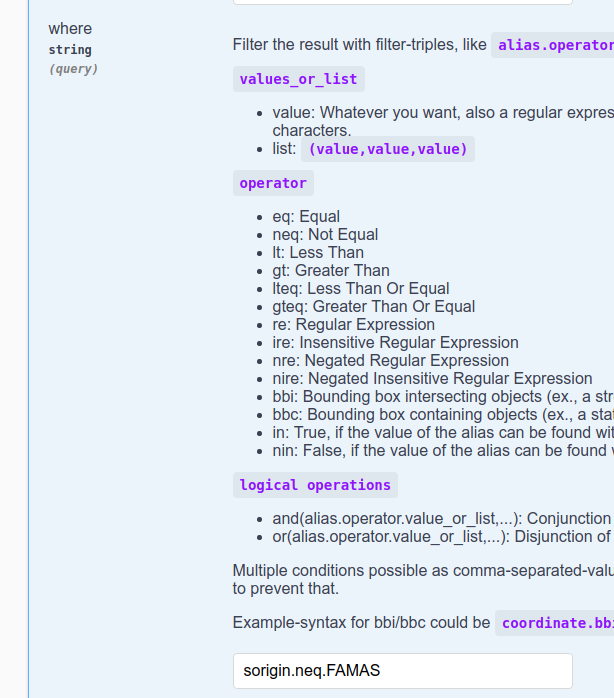
Figure 10 Non-FAMAS ParkingStations. |
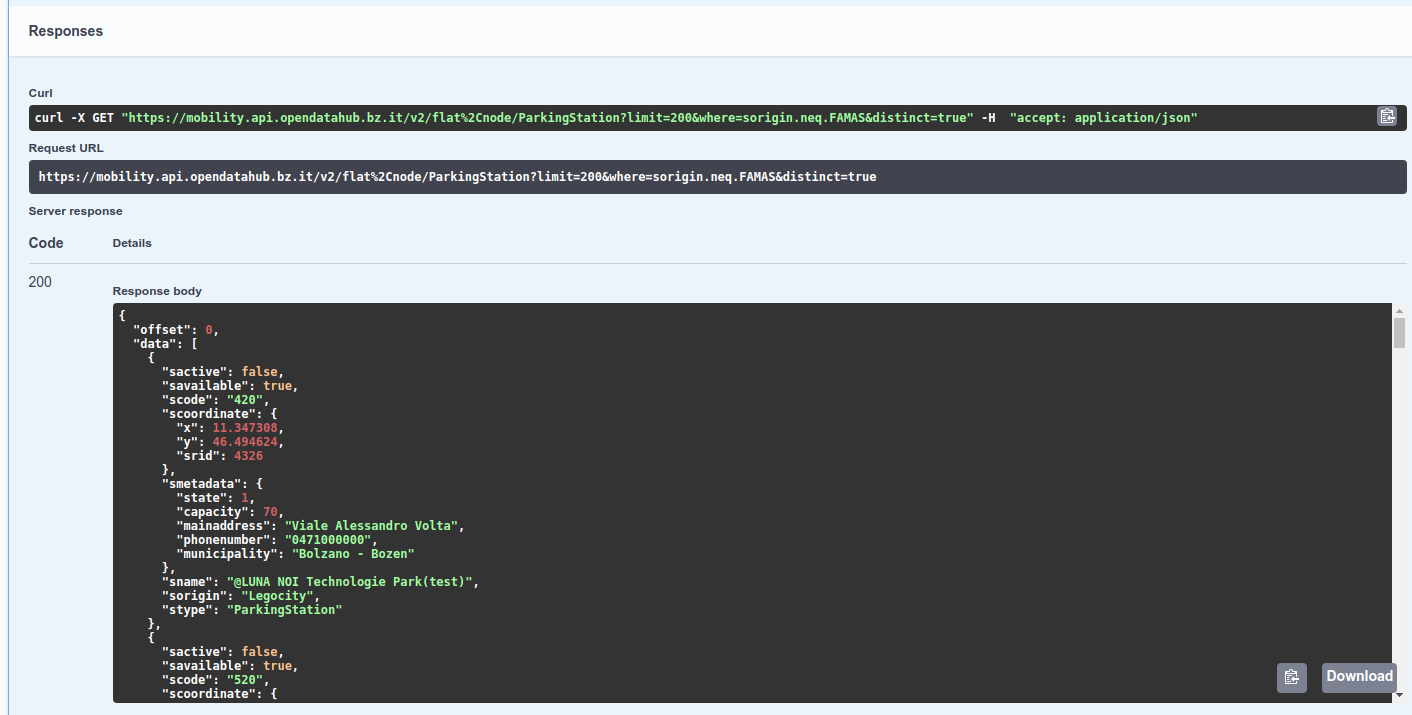
Figure 11 The Output of query. |
You can build more complex queries by simply adding more entries to the Select and where clauses.